#data science with AI ML training
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
US Tumblr user growth rate is estimated to slow down to 4.1%.
Text
Data Science with AI & ML Trends in 2023: Unleashing the Power of Data
In recent years, the convergence of data science, artificial intelligence (AI), and machine learning (ML) has revolutionized numerous industries, making data-driven decision-making a cornerstone of success.
As we venture into 2023, the domain of data science persists to evolve at a rapid pace, fueled by groundbreaking advancements in AI and ML technologies. This article explores the most significant trends in data science, AI, and ML that are shaping the landscape in 2023 and beyond.
Democratization of AI & ML:
One of the most prominent trends in 2023 is the democratization of AI and ML technologies. Previously, AI and ML were accessible mainly to large organizations with ample resources and technical expertise. However, advancements in automation, cloud computing, and the proliferation of user-friendly tools have lowered the entry barrier, allowing smaller businesses and individuals to leverage these technologies. Now, even non-experts can build and deploy sophisticated AI models, thereby unlocking new opportunities across various sectors.
Ethical AI & Responsible Data Science:
As AI applications become more prevalent, the need for ethical AI and responsible data science practices has become paramount. In 2023, organizations are placing a greater emphasis on ensuring fairness, transparency, and accountability in AI algorithms. Ethical considerations, such as bias mitigation, privacy protection, and model explainability, are crucial to building trust between AI systems and their users.
AI & ML at the Edge:
In 2023, edge computing is rapidly gaining traction as AI and ML are pushed closer to the data source, reducing latency and enhancing real-time processing capabilities. Edge AI enables devices such as smartphones, IoT devices, and sensors to process data locally, minimizing the reliance on cloud infrastructure. This trend is especially beneficial for applications requiring low latency and improved privacy.
Natural Language Processing (NLP) Advancements:
NLP has witnessed substantial progress in 2023, making machines able to understand and interact with human language more effectively. Chatbots, virtual assistants, and conversational AI have advanced significantly and can provide tailored and contextually appropriate answers. With advancements in language models and transformer architectures, NLP is reshaping industries like customer service, healthcare, and content generation.
Reinforcement Learning & Autonomous Systems:
Reinforcement learning, a subset of machine learning, is witnessing increased adoption in 2023. It enables AI systems to imbibe by establishing interactiveness with their environment and receiving feedback in the form of rewards. As a result, autonomous systems, such as self-driving cars, drones, and robots, are becoming more reliable and capable, pushing the boundaries of what is achievable with AI-powered automation.
Federated Learning for Privacy-Preserving AI:
Privacy concerns are becoming more prevalent as data collection and AI adoption increase. Federated learning, a decentralized approach to ML, is gaining popularity in 2023 as it allows training models on data from various sources without sharing the raw data itself. This enables organizations to derive insights collaboratively while preserving individual data privacy and security.
Quantum Machine Learning:
The burgeoning field of quantum machine learning is gaining momentum in 2023. Combining the principles of quantum computing with ML techniques, this new paradigm holds the potential to sort out complex problems beyond the abilities of classical computers. Although still in its infancy, quantum machine learning promises groundbreaking breakthroughs in optimization, cryptography, and drug discovery.
AI for Social Good:
In 2023, AI and ML are increasingly being harnessed for social good initiatives. From healthcare advancements to climate change mitigation and disaster response, these technologies are instrumental in addressing some of the world's most pressing challenges. Organizations and researchers are collaborating to deploy AI and ML solutions that have a positive impact on society and contribute to sustainable development.
Conclusion:
As we navigate through 2023, the data science landscape continues to be shaped by transformative trends in AI and ML technologies. The democratization of AI, ethical considerations, edge computing, NLP advancements, reinforcement learning, federated learning, quantum machine learning, and AI for social good are just a few of the key developments propelling the field forward.
Embracing these trends and harnessing the power of data science will undoubtedly drive innovation and reshape industries, enabling a brighter and more data-driven future. Data science with AI ML training is one of the most promising domains in today’s world!
0 notes
Text
The surprising truth about data-driven dictatorships

Here’s the “dictator’s dilemma”: they want to block their country’s frustrated elites from mobilizing against them, so they censor public communications; but they also want to know what their people truly believe, so they can head off simmering resentments before they boil over into regime-toppling revolutions.
These two strategies are in tension: the more you censor, the less you know about the true feelings of your citizens and the easier it will be to miss serious problems until they spill over into the streets (think: the fall of the Berlin Wall or Tunisia before the Arab Spring). Dictators try to square this circle with things like private opinion polling or petition systems, but these capture a small slice of the potentially destabiziling moods circulating in the body politic.
Enter AI: back in 2018, Yuval Harari proposed that AI would supercharge dictatorships by mining and summarizing the public mood — as captured on social media — allowing dictators to tack into serious discontent and diffuse it before it erupted into unequenchable wildfire:
https://www.theatlantic.com/magazine/archive/2018/10/yuval-noah-harari-technology-tyranny/568330/
Harari wrote that “the desire to concentrate all information and power in one place may become [dictators] decisive advantage in the 21st century.” But other political scientists sharply disagreed. Last year, Henry Farrell, Jeremy Wallace and Abraham Newman published a thoroughgoing rebuttal to Harari in Foreign Affairs:
https://www.foreignaffairs.com/world/spirals-delusion-artificial-intelligence-decision-making
They argued that — like everyone who gets excited about AI, only to have their hopes dashed — dictators seeking to use AI to understand the public mood would run into serious training data bias problems. After all, people living under dictatorships know that spouting off about their discontent and desire for change is a risky business, so they will self-censor on social media. That’s true even if a person isn’t afraid of retaliation: if you know that using certain words or phrases in a post will get it autoblocked by a censorbot, what’s the point of trying to use those words?
The phrase “Garbage In, Garbage Out” dates back to 1957. That’s how long we’ve known that a computer that operates on bad data will barf up bad conclusions. But this is a very inconvenient truth for AI weirdos: having given up on manually assembling training data based on careful human judgment with multiple review steps, the AI industry “pivoted” to mass ingestion of scraped data from the whole internet.
But adding more unreliable data to an unreliable dataset doesn’t improve its reliability. GIGO is the iron law of computing, and you can’t repeal it by shoveling more garbage into the top of the training funnel:
https://memex.craphound.com/2018/05/29/garbage-in-garbage-out-machine-learning-has-not-repealed-the-iron-law-of-computer-science/
When it comes to “AI” that’s used for decision support — that is, when an algorithm tells humans what to do and they do it — then you get something worse than Garbage In, Garbage Out — you get Garbage In, Garbage Out, Garbage Back In Again. That’s when the AI spits out something wrong, and then another AI sucks up that wrong conclusion and uses it to generate more conclusions.
To see this in action, consider the deeply flawed predictive policing systems that cities around the world rely on. These systems suck up crime data from the cops, then predict where crime is going to be, and send cops to those “hotspots” to do things like throw Black kids up against a wall and make them turn out their pockets, or pull over drivers and search their cars after pretending to have smelled cannabis.
The problem here is that “crime the police detected” isn’t the same as “crime.” You only find crime where you look for it. For example, there are far more incidents of domestic abuse reported in apartment buildings than in fully detached homes. That’s not because apartment dwellers are more likely to be wife-beaters: it’s because domestic abuse is most often reported by a neighbor who hears it through the walls.
So if your cops practice racially biased policing (I know, this is hard to imagine, but stay with me /s), then the crime they detect will already be a function of bias. If you only ever throw Black kids up against a wall and turn out their pockets, then every knife and dime-bag you find in someone’s pockets will come from some Black kid the cops decided to harass.
That’s life without AI. But now let’s throw in predictive policing: feed your “knives found in pockets” data to an algorithm and ask it to predict where there are more knives in pockets, and it will send you back to that Black neighborhood and tell you do throw even more Black kids up against a wall and search their pockets. The more you do this, the more knives you’ll find, and the more you’ll go back and do it again.
This is what Patrick Ball from the Human Rights Data Analysis Group calls “empiricism washing”: take a biased procedure and feed it to an algorithm, and then you get to go and do more biased procedures, and whenever anyone accuses you of bias, you can insist that you’re just following an empirical conclusion of a neutral algorithm, because “math can’t be racist.”
HRDAG has done excellent work on this, finding a natural experiment that makes the problem of GIGOGBI crystal clear. The National Survey On Drug Use and Health produces the gold standard snapshot of drug use in America. Kristian Lum and William Isaac took Oakland’s drug arrest data from 2010 and asked Predpol, a leading predictive policing product, to predict where Oakland’s 2011 drug use would take place.
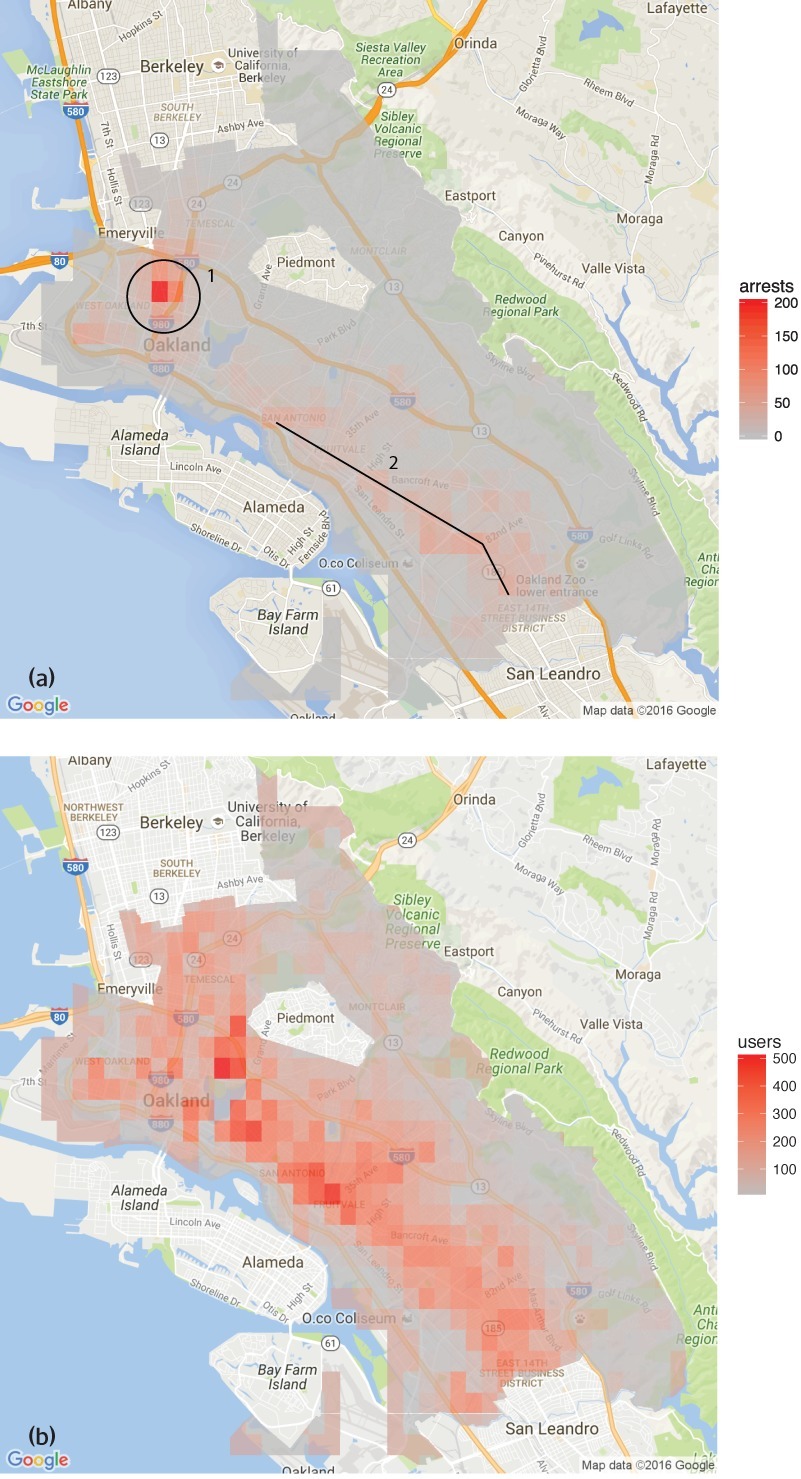
[Image ID: (a) Number of drug arrests made by Oakland police department, 2010. (1) West Oakland, (2) International Boulevard. (b) Estimated number of drug users, based on 2011 National Survey on Drug Use and Health]
Then, they compared those predictions to the outcomes of the 2011 survey, which shows where actual drug use took place. The two maps couldn’t be more different:
https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-9713.2016.00960.x
Predpol told cops to go and look for drug use in a predominantly Black, working class neighborhood. Meanwhile the NSDUH survey showed the actual drug use took place all over Oakland, with a higher concentration in the Berkeley-neighboring student neighborhood.
What’s even more vivid is what happens when you simulate running Predpol on the new arrest data that would be generated by cops following its recommendations. If the cops went to that Black neighborhood and found more drugs there and told Predpol about it, the recommendation gets stronger and more confident.
In other words, GIGOGBI is a system for concentrating bias. Even trace amounts of bias in the original training data get refined and magnified when they are output though a decision support system that directs humans to go an act on that output. Algorithms are to bias what centrifuges are to radioactive ore: a way to turn minute amounts of bias into pluripotent, indestructible toxic waste.
There’s a great name for an AI that’s trained on an AI’s output, courtesy of Jathan Sadowski: “Habsburg AI.”
And that brings me back to the Dictator’s Dilemma. If your citizens are self-censoring in order to avoid retaliation or algorithmic shadowbanning, then the AI you train on their posts in order to find out what they’re really thinking will steer you in the opposite direction, so you make bad policies that make people angrier and destabilize things more.
Or at least, that was Farrell(et al)’s theory. And for many years, that’s where the debate over AI and dictatorship has stalled: theory vs theory. But now, there’s some empirical data on this, thanks to the “The Digital Dictator’s Dilemma,” a new paper from UCSD PhD candidate Eddie Yang:
https://www.eddieyang.net/research/DDD.pdf
Yang figured out a way to test these dueling hypotheses. He got 10 million Chinese social media posts from the start of the pandemic, before companies like Weibo were required to censor certain pandemic-related posts as politically sensitive. Yang treats these posts as a robust snapshot of public opinion: because there was no censorship of pandemic-related chatter, Chinese users were free to post anything they wanted without having to self-censor for fear of retaliation or deletion.
Next, Yang acquired the censorship model used by a real Chinese social media company to decide which posts should be blocked. Using this, he was able to determine which of the posts in the original set would be censored today in China.
That means that Yang knows that the “real” sentiment in the Chinese social media snapshot is, and what Chinese authorities would believe it to be if Chinese users were self-censoring all the posts that would be flagged by censorware today.
From here, Yang was able to play with the knobs, and determine how “preference-falsification” (when users lie about their feelings) and self-censorship would give a dictatorship a misleading view of public sentiment. What he finds is that the more repressive a regime is — the more people are incentivized to falsify or censor their views — the worse the system gets at uncovering the true public mood.
What’s more, adding additional (bad) data to the system doesn’t fix this “missing data” problem. GIGO remains an iron law of computing in this context, too.
But it gets better (or worse, I guess): Yang models a “crisis” scenario in which users stop self-censoring and start articulating their true views (because they’ve run out of fucks to give). This is the most dangerous moment for a dictator, and depending on the dictatorship handles it, they either get another decade or rule, or they wake up with guillotines on their lawns.
But “crisis” is where AI performs the worst. Trained on the “status quo” data where users are continuously self-censoring and preference-falsifying, AI has no clue how to handle the unvarnished truth. Both its recommendations about what to censor and its summaries of public sentiment are the least accurate when crisis erupts.
But here’s an interesting wrinkle: Yang scraped a bunch of Chinese users’ posts from Twitter — which the Chinese government doesn’t get to censor (yet) or spy on (yet) — and fed them to the model. He hypothesized that when Chinese users post to American social media, they don’t self-censor or preference-falsify, so this data should help the model improve its accuracy.
He was right — the model got significantly better once it ingested data from Twitter than when it was working solely from Weibo posts. And Yang notes that dictatorships all over the world are widely understood to be scraping western/northern social media.
But even though Twitter data improved the model’s accuracy, it was still wildly inaccurate, compared to the same model trained on a full set of un-self-censored, un-falsified data. GIGO is not an option, it’s the law (of computing).
Writing about the study on Crooked Timber, Farrell notes that as the world fills up with “garbage and noise” (he invokes Philip K Dick’s delighted coinage “gubbish”), “approximately correct knowledge becomes the scarce and valuable resource.”
https://crookedtimber.org/2023/07/25/51610/
This “probably approximately correct knowledge” comes from humans, not LLMs or AI, and so “the social applications of machine learning in non-authoritarian societies are just as parasitic on these forms of human knowledge production as authoritarian governments.”

The Clarion Science Fiction and Fantasy Writers’ Workshop summer fundraiser is almost over! I am an alum, instructor and volunteer board member for this nonprofit workshop whose alums include Octavia Butler, Kim Stanley Robinson, Bruce Sterling, Nalo Hopkinson, Kameron Hurley, Nnedi Okorafor, Lucius Shepard, and Ted Chiang! Your donations will help us subsidize tuition for students, making Clarion — and sf/f — more accessible for all kinds of writers.
Libro.fm is the indie-bookstore-friendly, DRM-free audiobook alternative to Audible, the Amazon-owned monopolist that locks every book you buy to Amazon forever. When you buy a book on Libro, they share some of the purchase price with a local indie bookstore of your choosing (Libro is the best partner I have in selling my own DRM-free audiobooks!). As of today, Libro is even better, because it’s available in five new territories and currencies: Canada, the UK, the EU, Australia and New Zealand!
[Image ID: An altered image of the Nuremberg rally, with ranked lines of soldiers facing a towering figure in a many-ribboned soldier's coat. He wears a high-peaked cap with a microchip in place of insignia. His head has been replaced with the menacing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The sky behind him is filled with a 'code waterfall' from 'The Matrix.']
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
—
Raimond Spekking (modified) https://commons.wikimedia.org/wiki/File:Acer_Extensa_5220_-_Columbia_MB_06236-1N_-_Intel_Celeron_M_530_-_SLA2G_-_in_Socket_479-5029.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
—
Russian Airborne Troops (modified) https://commons.wikimedia.org/wiki/File:Vladislav_Achalov_at_the_Airborne_Troops_Day_in_Moscow_%E2%80%93_August_2,_2008.jpg
“Soldiers of Russia” Cultural Center (modified) https://commons.wikimedia.org/wiki/File:Col._Leonid_Khabarov_in_an_everyday_service_uniform.JPG
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#habsburg ai#self censorship#henry farrell#digital dictatorships#machine learning#dictator's dilemma#eddie yang#preference falsification#political science#training bias#scholarship#spirals of delusion#algorithmic bias#ml#Fully automated data driven authoritarianism#authoritarianism#gigo#garbage in garbage out garbage back in#gigogbi#yuval noah harari#gubbish#pkd#philip k dick#phildickian
833 notes
·
View notes
Text
Kickstart Your Tech Career: Why Internships Are More Important Than Ever
In the rapidly changing digital economy we live in today, a degree no longer suffices. What truly makes you stand out is practical experience—and that's where internships fit in.
If you are a computer science or IT bachelor's or master's degree holder, applying for a Java internship for freshers can prove to be one of the best decisions you ever took. Java remains a basis of enterprise software, and hence it is extremely important to study Java for those who are interested in working on backend development, application security, or web systems with scalability. Internships provide freshers with hands-on experience in writing optimized code, debugging, version control, and project collaboration.
On the opposite end, the world of technology is also eager for developers who excel at everything. This is why an full stack web development internship is a first preference for future professionals. With these internships, you get exposed to frontend and backend technologies—HTML, CSS, JavaScript, React, Node.js, Express, MongoDB, etc.—and you become a jack-of-all-trades of the world.
But above all, it is not that these internships simply teach you how to code, but how they teach you how to work, manage teams, deadlines, and deployable applications that solve real problems.
From product companies to tech startups or freelance work, the hands-on experience you learn through a concerted internship can define your career path. Theory is fine to learn, but experience is what gets you ready for a job.
#embedded systems course in Kerala#full stack java developer training in Kerala#python full stack developer course in Kerala#data analysis course for beginners#data analytics courses in kerala#full stack java developer course with placement#software developer internship in Kerala#java internship for freshers#full stack web development internship#software training institutes in kochi#best software training institute in kerala#best software training institute in trivandrum#software training institutes in kannur#best software training institute in calicut#data science course in kerala#data science and ai certification course#certification in ai and ml
1 note
·
View note
Text
Looking for an IT Training Institute Near Me? Choose Code with TLS for Success
If you're searching for an IT Training Institute Near Me, look no further than Code with TLS. As a leading Tech Course Provider, we offer a wide range of industry-relevant courses designed to help you gain the skills needed for a successful career in technology. Whether you're looking to switch careers, upskill, or start fresh in the tech world, Code with TLS is the perfect choice to help you achieve your goals.
Why Choose Code with TLS?
At Code with TLS, we understand that the right IT training can make all the difference in your career. That's why we provide top-tier courses that not only focus on the technical skills needed in today’s job market but also emphasize practical, hands-on learning. Our training programs are tailored to meet the needs of both beginners and professionals looking to advance in their careers.
As an IT Training Institute Near Me, we offer the following benefits:
Industry-Relevant Courses: From Digital Marketing and MERN Stack Development to Data Science and AI/ML, we provide courses that align with current industry trends and demand. Our curriculum is designed to ensure you gain expertise in the latest technologies.
Experienced Instructors: Learn from highly skilled professionals who bring real-world experience to the classroom. Our instructors are passionate about teaching and dedicated to helping you succeed.
100% Placement Assistance: One of the biggest challenges after completing training is securing a job. At Code with TLS, we help our students land their dream jobs through our 100% placement assistance program. We have partnered with over 650 companies to help students find the best opportunities.
Flexible Learning Options: Whether you prefer online courses or need an in-person classroom experience, we have flexible learning options to suit your schedule and preferences.
Personalized Support: Our team is always available to provide guidance and support throughout your training journey, ensuring you get the most out of your learning experience.
Start Your Tech Journey Today!
If you're ready to take the next step in your career and join one of the best IT Training Institutes Near Me, Code with TLS is here to help you succeed. Our expert instructors, comprehensive courses, and dedicated placement assistance will give you the edge you need to thrive in the tech industry.
Contact us today at +918527866980 to learn more about our courses and enroll in the program that suits your career goals. Let's make your tech dreams a reality!
#IT Training Institute Near Me#Best IT Training Institute#Tech Course Provider#Tech Training Near Me#IT Courses Near Me#Code with TLS#Digital Marketing Courses#MERN Stack Training#Data Science Training#AI/ML Courses#IT Career Training#Online IT Courses#Tech Skills Development#Job-Oriented IT Training#Placement Assistance IT Courses#Learn Tech Skills Near Me#Career in Tech#Coding Institute Near Me#IT Certification Courses#Professional IT Training
0 notes
Text

Discover how Machine Learning is shaping the modern world! This infographic explores 5 powerful real-world applications of Machine Learning across industries like healthcare, finance, transportation, and more. From fraud detection to self-driving cars, these examples show how ML is driving innovation and solving real-world problems.
Whether you're a tech enthusiast, student, or professional, this infographic offers a quick and visual insight into the practical power of Machine Learning.
🔍 Learn how you can master these skills with industry-relevant training at Nearlearn — a trusted name in AI & ML education.
Checkout the nearlearn website :https://nearlearn.com/courses/ai-and-machine-learning/machine-learning-with-python-training
#Machine Learning#Artificial Intelligence#Real World Applications#ML in Healthcare#Fraud Detection#Data Science#Nearlearn#AI Training#Tech Careers#Infographics#EdTech
0 notes
Text
AI & ML Training with Live Projects in Kolkata – Ejobindia
Ejobindia's AI & ML training program is tailored for both beginners and professionals aiming to delve into the world of AI. The course emphasizes hands-on learning, ensuring that students not only grasp theoretical concepts but also apply them in real-world scenarios.
Course Highlights
Duration: The program spans 100 hours, providing an in-depth understanding of AI and ML concepts.
Course Fee: The total fee for the course is ₹30,500.
Curriculum Includes:
Fundamentals of AI & ML
Prompt Engineering
Large Language Models (LLMs)
Industry Use Cases
Vector Databases
Hands-on assignments and live projects
This structured approach ensures that students gain both the theoretical knowledge and practical skills required in the AI industry.Home
Why Choose Ejobindia?
Industry-Relevant Training: The curriculum is designed in collaboration with industry experts to ensure relevance in today's job market.Home
Experienced Trainers: Learn from professionals with extensive experience in AI and ML.
Placement Support: Ejobindia boasts partnerships with over 100 hiring companies and facilitates approximately 300 placements annually.eJobIndia+1eJobIndia+1
Live Projects: Gain practical experience by working on real-world projects, enhancing your portfolio and confidence.
Flexible Learning Modes: Choose between online and offline classes based on your convenience.eJobIndia
Upcoming Batches
Ejobindia regularly updates its batch schedules. For the most recent information on upcoming batches, it's recommended to visit their official website or contact them directly.
How to Enroll
To enroll in the AI & ML Training with Live Projects in Kolkata at Ejobindia:
Visit the Official Website: Navigate to Ejobindia's AI & ML Training Page.eJobIndia
Contact: For direct inquiries, you can call them at 9830228812 / 9830125644 or email via the contact form on their website.eJobIndia
Fill Out the Enrollment Form: Provide the necessary details and choose your preferred batch timing.
Embark on your AI journey with Ejobindia and equip yourself with the skills to thrive in the ever-evolving tech landscape.
#AI & ML Training with Live Projects in Kolkata#AI and Data Science Training in Kolkata#AI Training in Kolkata
0 notes
Text
Natural Language Processing: Beyond Chatbots and Translation
Natural Language Processing (NLP), a subfield of artificial intelligence, has evolved far beyond its initial applications of chatbots and translation. As the volume of unstructured data grows, NLP has emerged as a vital tool for extracting actionable insights from text, audio, and even video content. From improving customer experience to powering cutting-edge research, NLP’s potential spans industries, transforming how we interact with technology and information.
The Expanding Role of NLP in Industries
NLP is revolutionizing industries by enabling machines to understand and interpret human language. For example, in healthcare, NLP systems analyze clinical notes to identify patterns, predict patient outcomes, and even detect diseases early. Similarly, in the financial sector, NLP aids in fraud detection by scanning vast datasets for anomalies in transaction patterns. The retail sector benefits from NLP-driven sentiment analysis, which provides insights into customer opinions and preferences.
Text Analytics: Mining Insights from Unstructured Data
One of the most transformative applications of NLP is in text analytics. Organizations deal with massive amounts of unstructured text, such as emails, reviews, and social media posts. NLP tools can process this data, categorizing it into actionable insights.
For instance, topic modeling algorithms group text into themes, making it easier to understand customer concerns or emerging trends. Sentiment analysis tools analyze text to determine the emotional tone, enabling businesses to respond proactively to customer feedback.
Speech Recognition and Audio Processing
NLP isn’t confined to text; it’s also redefining how machines understand spoken language. Speech-to-text tools like Google Speech API and Amazon Transcribe are helping businesses convert audio data into analyzable formats.
In addition to transcription, NLP-powered audio processing enables voice-controlled applications like virtual assistants and automated customer support systems. Industries like automotive are using speech recognition for hands-free control in vehicles, while healthcare leverages it to transcribe medical dictations accurately.
Transforming Research with NLP
NLP is a game-changer for researchers who are handling vast amounts of literature. Tools like Semantic Scholar and PubMed NLP models sift through thousands of research papers to extract relevant information.
This capability accelerates discoveries in fields like medicine, where NLP helps identify correlations in studies that may have otherwise been overlooked. Such tools not only save time but also enhance the quality of research outcomes.
The Future of NLP: Emerging Trends
As NLP continues to advance, emerging trends like transformer-based models are pushing the boundaries of what’s possible. Models like GPT and BERT have revolutionized the accuracy of language understanding, enabling more nuanced applications such as automated content creation and sentiment-aware chatbots.
Moreover, ethical considerations are becoming a focal point in NLP. Ensuring unbiased training data and transparent algorithms will be critical for building systems that serve diverse global populations equitably.
Transforming NLP in a Data-Driven World
NLP is transforming industries, enabling applications far beyond chatbots and translation. Its ability to process and analyze unstructured data makes it indispensable in today’s data-driven world. Data science AI ML training equips professionals with the skills to harness NLP’s full potential, empowering them to drive innovation across sectors. Ascendient Learning offers cutting-edge training programs designed to help individuals and teams excel in NLP and related AI technologies.
To learn more about our services, visit: https://www.ascendientlearning.com/it-training/generative-ai/intro-genai-dsml-67967-detail.html
0 notes
Text
Descriptive Statistics: The Starting Point for Machine Learning - Mean, Median & Mode
Introduction
Did you know that the simple concepts of mean, median, and mode that most students learn in high school or college are part of something much bigger called descriptive statistics? These are not just formulas to memorize for exams, but powerful tools that help us make sense of the world, especially in the realm of machine learning.

If you’ve ever used a weather app, checked the average price of a product, or wondered how your exam scores compare to others, you’ve already encountered descriptive statistics in action. These concepts are the foundation of data analysis, helping us summarize large amounts of information into digestible insights. Whether you're an academic, a data scientist, or just someone working with numbers, understanding these can be incredibly beneficial.
In this blog, we’ll explore mean, median, and mode in simple, relatable terms. You’ll learn why they matter, how they’re used, and how they can even reveal surprising patterns in data. By the end, you’ll see these tools as more than just numbers—they’re a way to understand and tell stories with data.
What Are Descriptive Statistics?
Descriptive statistics are like a summary of a book. Imagine you have a giant dataset filled with numbers. Instead of analyzing every single number individually, descriptive statistics let you condense all that information into a few key takeaways.
Think of descriptive statistics as the answers to these questions:
What is the typical value in the data?
How spread out are the numbers?
Are there any unusual numbers (outliers) in the dataset?
These tools don’t just organize data; they help us make decisions. For example, a sports coach might use descriptive statistics to figure out an average player’s performance, or a teacher might use it to understand how a class performed on a test.
Key Terms
Mean (Average): Represents the typical value of your dataset.
Median (Middle Value): The middle number in a sorted dataset.
Mode (Most Frequent Value): The value that appears most often.
These concepts sound simple, but their real-world applications are profound. Let’s dive deeper into each one.
Mean: The Average Value
The mean is the first thing people think of when summarizing data. It’s the average—a single number that represents the entire dataset.
How to Calculate the Mean
To find the mean:
Add up all the numbers in the dataset.
Divide by the total number of values.
Real-World Example
Imagine your test scores over five exams are: 80, 85, 90, 75, and 95. To calculate the mean:
Add: 80 + 85 + 90 + 75 + 95 = 425
Divide: 425 ÷ 5 = 85
The mean score is 85. This tells you that, on average, you scored 85 on your tests.
Why the Mean Is Useful
The mean helps you understand the “typical” value of a dataset. If you’re a teacher, the mean class score can tell you how well students performed overall. If you’re a business owner, the mean monthly sales can help you track growth.
Limitations of the Mean
The mean can be misleading when there are outliers. Outliers are values that are much higher or lower than the rest of the data.
Example of Outliers: Imagine your test scores are: 80, 85, 90, 75, and 300. The mean becomes:
Add: 80 + 85 + 90 + 75 + 300 = 630
Divide: 630 ÷ 5 = 126
Does 126 represent your performance? Not really! That one outlier (300) skews the mean, making it higher than most of your scores.
Median: The Middle Value
The median is the middle number in a dataset when it’s sorted in order. Unlike the mean, the median isn’t affected by outliers, making it a more accurate representation of data in certain cases.
How to Calculate the Median
Arrange the data in ascending order.
Find the middle value.
If there’s an odd number of values, the median is the middle one.
If there’s an even number of values, the median is the average of the two middle numbers.
Real-World Example
Your daily spending over a week: 30, 40, 45, 50, 100.
Arrange: 30, 40, 45, 50, 100
Median = 45 (middle value)
If an outlier changes your spending to 30, 40, 45, 50, 1000, the median stays at 45. This stability makes the median useful when dealing with skewed data.
Why the Median Is Useful
The median is great for datasets with extreme values or skewed distributions, such as house prices. For example, if most houses in a neighbourhood cost $200,000 but one mansion costs $10 million, the median price gives a clearer picture of the typical home instead of the anomalies. If a family is planning to buy a house and they look at the mean, and it is very high they probably would not want to buy the house that’s where median comes into play. Median gives a clearer picture of the normal prices instead of the outliers.
Mode: The Most Frequent Value
The mode is the value that appears most often in a dataset. It’s especially useful for categorical data or finding trends.
How to Find the Mode
Count how many times each value appears.
The value with the highest count is the mode.
Real-World Example
Survey responses about favourite ice cream flavours: Vanilla, Chocolate, Chocolate, Strawberry, Vanilla, Chocolate.
Vanilla - 2
Strawberry - 1
Chocolate - 3
Mode = Chocolate (appears 3 times).
Why the Mode Is Useful
The mode helps identify popularity or commonality. For instance, in marketing, knowing the most purchased product can guide inventory decisions, like which product do we stock up on.
Summary Each Concept
Mean: Calculate by adding all numbers and dividing by the count. Useful for getting the "average" but can be skewed by outliers.
Median: Found by arranging data and picking the middle value. Excellent for skewed data because it's not influenced by outliers.
Mode: Identified by finding the most frequent data point. Great for understanding commonality or popularity in categorical data.
Conclusion
Descriptive statistics aren’t just numbers; they’re tools that help us make sense of data and the world around us. By understanding mean, median, mode, variance, and standard deviation, you can:
Summarize data quickly.
Identify patterns and outliers.
Prepare data for deeper analysis in machine learning.
So, the next time you see a dataset, don’t just glance over it—ask yourself: What story is this data telling? With descriptive statistics, you have the power to find out.
Insights with Descriptive Statistics
Through mean, median, and mode, descriptive statistics allow us to quickly summarize data, identify patterns, and prepare for more complex analyses. These concepts aren't just tools for calculation; they offer us ways to view and interpret the vast amounts of data that inform decisions in fields ranging from education to economics.
You might be wondering why I've mentioned Variance and Standard Deviation towards the end. This is because these concepts are fundamental in descriptive statistics and are vital for machine learning and data analysis. Variance and Standard Deviation provide us with insights into the spread and variability of data, aspects that mean, median, and mode cannot capture alone.
If you feel you're falling behind in any of these areas or have a keen interest in learning machine learning, now is the time to act. Pydun Technology’s specialized training programs are designed to equip you with the skills and confidence to overcome obstacles and master complex concepts.
At Pydun, we believe the journey isn’t just about hard work—it’s about simplifying complexity, understanding the core principles, and connecting these concepts to real-world applications.
Are you ready to transform your academic and professional journey? Contact us today at [email protected] or drop us a message at +91 93619 99189 and take the first step toward becoming the learner you were destined to be.
Stay tuned for the next blog where we will delve deeper into how Variance and Standard Deviation play a crucial role in understanding data spread and variability. This knowledge not only enhances our ability to summarize data but also helps in predicting and controlling future outcomes in complex data environments.
#Machine Learning#Machine Learning with AI#AI courese#Artificial Intelligence and Machine Learning Courses#Artificial Intelligence Courses#Machine Learning Courses#AI Courses in Madurai#AI and ML Training in Madurai#AI Programming in Madurai#Machine Learning Training in Madurai#Data Science and Analytics with AI#Data Science and Analytics with AI Courses
1 note
·
View note
Text
BTech CSE: Your Gateway to High-Demand Tech Careers
Apply now for admission and avail the Early Bird Offer
In the digital age, a BTech in Computer Science & Engineering (CSE) is one of the most sought-after degrees, offering unmatched career opportunities across industries. From software development to artificial intelligence, the possibilities are endless for CSE graduates.
Top Job Opportunities for BTech CSE Graduates
Software Developer: Design and develop innovative applications and systems.
Data Scientist: Analyze big data to drive business decisions.
Cybersecurity Analyst: Safeguard organizations from digital threats.
AI/ML Engineer: Lead the way in artificial intelligence and machine learning.
Cloud Architect: Build and maintain cloud-based infrastructure for global organizations.
Why Choose Brainware University for BTech CSE?
Brainware University provides a cutting-edge curriculum, hands-on training, and access to industry-leading tools. Our dedicated placement cell ensures you’re job-ready, connecting you with top recruiters in tech.
👉 Early Bird Offer: Don’t wait! Enroll now and take the first step toward a high-paying, future-ready career in CSE.
Your journey to becoming a tech leader starts here!
#n the digital age#a BTech in Computer Science & Engineering (CSE) is one of the most sought-after degrees#offering unmatched career opportunities across industries. From software development to artificial intelligence#the possibilities are endless for CSE graduates.#Top Job Opportunities for BTech CSE Graduates#Software Developer: Design and develop innovative applications and systems.#Data Scientist: Analyze big data to drive business decisions.#Cybersecurity Analyst: Safeguard organizations from digital threats.#AI/ML Engineer: Lead the way in artificial intelligence and machine learning.#Cloud Architect: Build and maintain cloud-based infrastructure for global organizations.#Why Choose Brainware University for BTech CSE?#Brainware University provides a cutting-edge curriculum#hands-on training#and access to industry-leading tools. Our dedicated placement cell ensures you’re job-ready#connecting you with top recruiters in tech.#👉 Early Bird Offer: Don’t wait! Enroll now and take the first step toward a high-paying#future-ready career in CSE.#Your journey to becoming a tech leader starts here!#BTechCSE#BrainwareUniversity#TechCareers#SoftwareEngineering#AIJobs#EarlyBirdOffer#DataScience#FutureOfTech#Placements
1 note
·
View note
Text

Hands-On Data Science Training Kerala
Master data science with real-world projects, ML, and AI in Kerala. Join the best training course today. https://www.qisacademy.com/course/advanced-diploma-in-data-science-ml-ai
#Best Data Science ML& AI course in kerala#data science course in kerala#data science training#Best Machine Learning Training in Kerala#Data science ML & AI training in kerala
0 notes
Text
AI, ML, and Big Data: What to Expect from Advanced Data Science Training in Marathahalli
AI, ML, and Big Data: What to Expect from Advanced Data Science Training in Marathahalli
Data science has emerged as one of the most critical fields in today’s tech-driven world. The fusion of Artificial Intelligence (AI), Machine Learning (ML), and Big Data analytics has changed the landscape of businesses across industries. As industries continue to adopt data-driven strategies, the demand for skilled data scientists, particularly in emerging hubs like Marathahalli, has seen an exponential rise.
Institutes in Marathahalli are offering advanced training in these crucial areas, preparing students to be future-ready in the fields of AI, ML, and Big Data. Whether you are seeking Data Science Training in Marathahalli, pursuing a Data Science Certification Marathahalli, or enrolling in a Data Science Bootcamp Marathahalli, these courses are designed to provide the hands-on experience and theoretical knowledge needed to excel.
AI and Machine Learning: Transforming the Future of Data Science
Artificial Intelligence and Machine Learning are at the forefront of modern data science. Students enrolled in AI and Data Science Courses in Marathahalli are introduced to the core concepts of machine learning algorithms, supervised and unsupervised learning, neural networks, deep learning, and natural language processing (NLP). These are essential for creating systems that can think, learn, and evolve from data.
Institutes in Marathahalli offering AI and ML training integrate real-world applications and projects to make sure that students can translate theory into practice. A Machine Learning Course Marathahalli goes beyond teaching the mathematical and statistical foundations of algorithms to focus on practical applications such as predictive analytics, recommender systems, and image recognition.
Data Science students gain proficiency in Python, R, and TensorFlow for building AI-based models. The focus on AI ensures that graduates of Data Science Classes Bangalore are highly employable in AI-driven industries, from automation to finance.
Key topics covered include:
Supervised Learning: Regression, classification, support vector machines
Unsupervised Learning: Clustering, anomaly detection, dimensionality reduction
Neural Networks: Deep learning models like CNN, RNN, and GANs
Natural Language Processing (NLP): Text analysis, sentiment analysis, chatbots
Model Optimization: Hyperparameter tuning, cross-validation, regularization
By integrating machine learning principles with AI tools, institutes like Data Science Training Institutes Near Marathahalli ensure that students are not just skilled in theory but are also ready for real-world challenges.
Big Data Analytics: Leveraging Large-Scale Data for Business Insights
With the advent of the digital age, businesses now have access to enormous datasets that, if analyzed correctly, can unlock valuable insights and drive innovation. As a result, Big Data Course Marathahalli has become a cornerstone of advanced data science training. Students are taught to work with massive datasets using advanced technologies like Hadoop, Spark, and NoSQL databases to handle, process, and analyze data at scale.
A Big Data Course Marathahalli covers crucial topics such as data wrangling, data storage, distributed computing, and real-time analytics. Students are equipped with the skills to process unstructured and structured data, design efficient data pipelines, and implement scalable solutions that meet the needs of modern businesses. This hands-on experience ensures that they can manage data at the petabyte level, which is crucial for industries like e-commerce, healthcare, finance, and logistics.
Key topics covered include:
Hadoop Ecosystem: MapReduce, HDFS, Pig, Hive
Apache Spark: RDDs, DataFrames, Spark MLlib
Data Storage: NoSQL databases (MongoDB, Cassandra)
Real-time Data Processing: Kafka, Spark Streaming
Data Pipelines: ETL processes, data lake architecture
Institutes offering Big Data Course Marathahalli prepare students for real-time data challenges, making them skilled at developing solutions to handle the growing volume, velocity, and variety of data generated every day. These courses are ideal for individuals seeking Data Analytics Course Marathahalli or those wanting to pursue business analytics.
Python for Data Science: The Language of Choice for Data Professionals
Python has become the primary language for data science because of its simplicity and versatility. In Python for Data Science Marathahalli courses, students learn how to use Python libraries such as NumPy, Pandas, Scikit-learn, Matplotlib, and Seaborn to manipulate, analyze, and visualize data. Python’s ease of use, coupled with powerful libraries, makes it the preferred language for data scientists and machine learning engineers alike.
Incorporating Python into Advanced Data Science Marathahalli training allows students to learn how to build and deploy machine learning models, process large datasets, and create interactive visualizations that provide meaningful insights. Python’s ability to work seamlessly with machine learning frameworks like TensorFlow and PyTorch also gives students the advantage of building cutting-edge AI models.
Key topics covered include:
Data manipulation with Pandas
Data visualization with Matplotlib and Seaborn
Machine learning with Scikit-learn
Deep learning with TensorFlow and Keras
Web scraping and automation
Python’s popularity in the data science community means that students from Data Science Institutes Marathahalli are better prepared to enter the job market, as Python proficiency is a sought-after skill in many organizations.
Deep Learning and Neural Networks: Pushing the Boundaries of AI
Deep learning, a subfield of machine learning that involves training artificial neural networks on large datasets, has become a significant force in fields such as computer vision, natural language processing, and autonomous systems. Students pursuing a Deep Learning Course Marathahalli are exposed to advanced techniques for building neural networks that can recognize patterns, make predictions, and improve autonomously with exposure to more data.
The Deep Learning Course Marathahalli dives deep into algorithms like convolutional neural networks (CNN), recurrent neural networks (RNN), and reinforcement learning. Students gain hands-on experience in training models for image classification, object detection, and sequence prediction, among other applications.
Key topics covered include:
Neural Networks: Architecture, activation functions, backpropagation
Convolutional Neural Networks (CNNs): Image recognition, object detection
Recurrent Neural Networks (RNNs): Sequence prediction, speech recognition
Reinforcement Learning: Agent-based systems, reward maximization
Transfer Learning: Fine-tuning pre-trained models for specific tasks
For those seeking advanced knowledge in AI, AI and Data Science Course Marathahalli is a great way to master the deep learning techniques that are driving the next generation of technological advancements.
Business Analytics and Data Science Integration: From Data to Decision
Business analytics bridges the gap between data science and business decision-making. A Business Analytics Course Marathahalli teaches students how to interpret complex datasets to make informed business decisions. These courses focus on transforming data into actionable insights that drive business strategy, marketing campaigns, and operational efficiencies.
By combining advanced data science techniques with business acumen, students enrolled in Data Science Courses with Placement Marathahalli are prepared to enter roles where data-driven decision-making is key. Business analytics tools like Excel, Tableau, Power BI, and advanced statistical techniques are taught to ensure that students can present data insights effectively to stakeholders.
Key topics covered include:
Data-driven decision-making strategies
Predictive analytics and forecasting
Business intelligence tools: Tableau, Power BI
Financial and marketing analytics
Statistical analysis and hypothesis testing
Students who complete Data Science Bootcamp Marathahalli or other job-oriented courses are often equipped with both technical and business knowledge, making them ideal candidates for roles like business analysts, data consultants, and data-driven managers.
Certification and Job Opportunities: Gaining Expertise and Career Advancement
Data Science Certification Marathahalli programs are designed to provide formal recognition of skills learned during training. These certifications are recognized by top employers across the globe and can significantly enhance career prospects. Furthermore, many institutes in Marathahalli offer Data Science Courses with Placement Marathahalli, ensuring that students not only acquire knowledge but also have the support they need to secure jobs in the data science field.
Whether you are attending a Data Science Online Course Marathahalli or a classroom-based course, placement assistance is often a key feature. These institutes have strong industry connections and collaborate with top companies to help students secure roles in data science, machine learning, big data engineering, and business analytics.
Benefits of Certification:
Increased job prospects
Recognition of technical skills by employers
Better salary potential
Access to global job opportunities
Moreover, institutes offering job-oriented courses such as Data Science Job-Oriented Course Marathahalli ensure that students are industry-ready, proficient in key tools, and aware of the latest trends in data science.
Conclusion
The Data Science Program Marathahalli is designed to equip students with the knowledge and skills needed to thrive in the fast-evolving world of AI, machine learning, and big data. By focusing on emerging technologies and practical applications, institutes in Marathahalli prepare their students for a wide array of careers in data science, analytics, and AI. Whether you are seeking an in-depth program, a short bootcamp, or an online certification, there are ample opportunities to learn and grow in this exciting field.
With the growing demand for skilled data scientists, Data Science Training Marathahalli programs ensure that students are prepared to make valuable contributions to their future employers. From foundational programming to advanced deep learning and business analytics, Marathahalli offers some of the best data science courses that cater to diverse needs, making it an ideal destination for aspiring data professionals.
Hashtags:
#DataScienceTrainingMarathahalli #BestDataScienceInstitutesMarathahalli #DataScienceCertificationMarathahalli #DataScienceClassesBangalore #MachineLearningCourseMarathahalli #BigDataCourseMarathahalli #PythonForDataScienceMarathahalli #AdvancedDataScienceMarathahalli #AIandDataScienceCourseMarathahalli #DataScienceBootcampMarathahalli #DataScienceOnlineCourseMarathahalli #BusinessAnalyticsCourseMarathahalli #DataScienceCoursesWithPlacementMarathahalli #DataScienceProgramMarathahalli #DataAnalyticsCourseMarathahalli #RProgrammingForDataScienceMarathahalli #DeepLearningCourseMarathahalli #SQLForDataScienceMarathahalli #DataScienceTrainingInstitutesNearMarathahalli #DataScienceJobOrientedCourseMarathahalli
0 notes
Text
Advancing Technology: The New Developments in Data Science, AI, and ML Training
As industries become increasingly data-driven, the demand for professionals skilled in data science, AI, and machine learning (ML) is at an all-time high. These fields are reshaping business processes, creating more intelligent systems, and driving innovation across sectors such as healthcare, finance, and retail. With technologies rapidly evolving, professionals must stay updated through comprehensive data science, AI, ML training programs to remain competitive in their careers and drive impactful innovations across sectors.
New Trends in Data Science, AI, and ML
New trends are transforming how data science, AI, and ML are used across industries. Explainable AI (XAI) focuses on making machine learning models more transparent, helping build trust in AI-driven decisions. This is crucial for fields like healthcare and autonomous driving, where understanding AI decisions is vital. Additionally, Federated Learning allows machine learning models to train across multiple devices without sharing raw data, addressing privacy concerns in sensitive industries like healthcare and finance, where data security is essential.
The Role of Automation and AutoML
Automation is revolutionizing data science and AI workflows. AutoML (Automated Machine Learning) is a game-changer that allows developers to automate tasks such as feature engineering, model selection, and hyperparameter tuning, significantly reducing the time and expertise required to develop high-performing models. AutoML is particularly beneficial for businesses that want to implement machine learning solutions but lack the in-house expertise to build models from scratch. Moreover, automation enables faster deployment and scalability, allowing organizations to stay ahead of competitors and respond quickly to market demands.
Additionally, tools like DataRobot and Google’s AutoML are empowering non-technical teams to harness the power of AI and ML without deep coding knowledge. Professionals who undergo data science, AI, and ML training gain hands-on experience with these automation tools, preparing them for real-world applications and equipping them to lead innovation in their organizations.
Why Data Science, AI, and ML Training is Essential
With rapid technological advancements, continuous learning is essential for professionals in data science, AI, and ML. Training programs have evolved beyond basic tools like Python and TensorFlow, covering new frameworks, ethical considerations, and innovations in deep learning and neural networks. Additionally, training emphasizes data governance, which is crucial as companies handle increasing amounts of sensitive data. Understanding how to manage and secure large datasets is vital for any data professional. Data science, AI, ML training equips professionals to apply these technologies in practical scenarios, from personalized recommendations to predictive modeling for business efficiency.
Preparing for the Future with Data Science, AI, and ML Training
In an era of rapid technological change, investing in data science, AI, ML training is essential to staying competitive. These programs equip professionals with the latest tools and techniques while preparing them to implement cutting-edge solutions in their respective industries. Web Age Solutions offers comprehensive training, ensuring participants gain the expertise necessary to excel in this rapidly evolving landscape and drive future advancements in their fields. This investment helps professionals future-proof their careers while positioning organizations for sustained success in a data-driven world.
For more information visit: https://www.webagesolutions.com/courses/data-science-ai-ml-training
0 notes
Text
Elevate Your Data Science Skills with Data Science Course in Pune

Success in the rapidly evolving field of data science hinges on one key factor: quality data. Before diving into more complex machine learning algorithms and detailed analysis, starting with a clean data set is important. At The Cyber Success Institute, our Data Science Course in Pune emphasizes mastering these core skills, equipping you with the expertise to handle data efficiently and drive impactful results. These basic data cleaning steps, known as data wrangling and preprocessing, are necessary to process raw data in sophisticated ways that support accurate analysis and prediction to hone these basic skills to process data thoroughly and prepare amazing results A resource that gives you essential knowledge.
Transform Your Career with The Best Data Science Course at Cyber Success
Data wrangling, or data manging, is the process of transforming and processing raw data from its often messy origin into a more usable form. This process involves preparing, organizing, and enhancing data to make it more valuable for analysis and modeling. Preprocessing, which is less controversial, focuses primarily on preparing data for machine learning models to normalize, transform, and scale them to improve performance
At the Cyber Success Institute, we understand that strong data disputes are the cornerstone of any data science project. Our Data Science Course in Pune offers hands-on training in data wrangling and pre-processing, enabling you to effectively transform raw data into actionable insights.
Discover Data Cleaning Excellence with The Best Data Science Course at Cyber Success
The data management process involves preparing, organizing, and enhancing the data to make it more valuable for analysis and modeling. Less controversial preprocessing focuses on data preparation for machine learning models to ensure performance data quality will directly affect the accuracy and reliability of machine learning models The information is well suited and ensures insights are accurate and useful. This helps to identify hidden patterns and saves time during sample development and subsequent analysis. At Cyber Success Institute, we focus on the importance of data security requirements so we prepare you and your employees to ensure that your data is always up to date. Our Data Science Course in Pune offers hands-on training in data wrangling and pre-processing, enabling you to effectively transform raw data into actionable insights. Basic Steps in Data Management and Preprocessing,
Data cleaning: This first and most important step includes handling missing values, eliminating inconsistencies, and eliminating redundant data points. Effective data cleaning ensures that the dataset is reliable, it is accurate and ready for analysis.
Data conversion: Once prepared, the data must be converted to usable form. This may involve converting categorical variables into numeric ones using techniques such as one-hot encoding or label encoding. Normalization and standardization are used to ensure that all factors contribute to the equality of the model, with no feature dominating due to scale differences make sure you are prepared to handle a variety of data environments.
Feature Engineering: Feature engineering is the process of creating new features from existing data to better capture underlying patterns. This may involve forming interactive phrases, setting attributes, or decomposing timestamps into more meaningful objects such as "day of the week" or "hour of the day".
Data reduction: Sometimes data sets can have too many or too many dimensions, which can lead to overqualification or computational costs. Data reduction techniques such as principal component analysis (PCA), feature selection, and dimensionality reduction are essential to simplify data sets while preserving valuable information Our Data Science Classes in Pune with Placement at the Cyber Success Institute provide valuable experience in data reduction techniques to help you manage large data sets effectively.
Data integration and consolidation: Often, data from multiple sources must be combined to obtain complete data. Data integration involves combining data from databases or files into a combined data set. In our Data Science Course in Pune, you will learn how to combine different types of data to improve and increase the relevance and depth of research.

Why Choose Cyber Success Institute for Data Science Course in Pune?
The Cyber Success Institute is the best IT training institute in Pune, India, offering the best data science course in Pune with Placement assistance, designed to give you a deep understanding of data science from data collection to preprocessing to advanced machine learning. With hands-on experience, expert guidance and a curriculum that is up to date with the latest industry trends, you will be ready to become a data scientist
Here are the highlights of the data science course at Cyber Success Institute, Pune:
Experienced Trainers: Our data science expert trainers bring a wealth of experience in the field of data science, including advanced degrees, industry certifications, strong backgrounds in data analytics, machine learning, AI, and hands-on experience in real-world projects to ensure students learn Entrepreneurs who understand business needs.
Advanced Curriculum: Our Data Science Course in Pune is well structured to cover basic and advanced topics in data science, including Python programming, statistics, data visualization, machine learning, deep learning natural language processing and big data technology.
Free Aptitude Sessions: We believe that strong analytical and problem-solving skills are essential in data science. To support technical training, we offer free aptitude sessions that focus on developing logical reasoning, statistical analysis and critical thinking.
Weekly Mock Interview Sessions: To prepare you for the job, we conduct weekly mock interview sessions that simulate real-world interview situations. These sessions include technical quizzes on data science concepts, coding problems, and behavioral quizzes to build student confidence and improve interview performance.
Hands-on Learning: Our Data Science Course in Pune emphasizes practical, hands-on learning. You will work on real-world projects, data manipulation, machine learning model development, and applications using tools such as Python and Tableau. This approach ensures a deep and practical understanding of data science, preparing them for real job challenges.
100% Placement Assistance: We provide comprehensive placement assistance to help you start your career in data science. This includes writing a resume, preparing for an interview, and connecting with potential employers.
At Cyber Success, our Data Science Course in Pune ensures that students receive a well-rounded education that combines theoretical knowledge with practical experience. We are committed to helping our students become skilled, confident and career-ready data scientists.
Conclusion:
Data management and preprocessing are the unsung heroes of data science, transforming raw data into powerful insights that shape the future. At Cyber Success Institute, our Data Science Course in Pune will teach you the technical skills and it will empower you to lead the data revolution. With immersive, hands-on training, real-world projects, and mentorship from industry experts, we prepare you to harness data’s full potential and drive meaningful impact. Joining Cyber Success Institute, it’s about becoming part of a community committed to excellence and innovation. Start your journey here, master the art of data science with our Data Science Course in Pune, and become a change-maker in this rapidly growing field. Elevate your career, lead with data, and let Cyber Success Institute be your launchpad to success. Your future in data science starts now!
Attend 2 free demo sessions!
To learn more about our course at, https://www.cybersuccess.biz/data-science-course-in-pune/
Secure your place at, https://www.cybersuccess.biz/contact-us/
📍 Our Visit: Cyber Success, Asmani Plaza, 1248 A, opp. Cafe Goodluck, Pulachi Wadi, Deccan Gymkhana, Pune, Maharashtra 411004
📞 For more information, call: 9226913502, 9168665644, 7620686761.
PATH TO SUCCESS - CYBER SUCCESS 👍
#education#training#itinstitute#datascience#big data#data analytics#data cleaning techniques#deep learning#machine learning#ai ml development services#python programming#data science course in Pune#data science classes in pune#data science course with placement in pune#career#mongodb#statistics#data science training institute
0 notes
Text
Discover the Best Tech Courses at Code with TLS | IT Training Institute Near Me
Are you looking for a reliable IT Training Institute Near Me that offers top-notch tech courses to help you advance your career? Look no further than Code with TLS, a leading Tech Course Provider in India. With a comprehensive range of IT training programs and expert instructors, we are here to help you develop the skills you need to succeed in the competitive tech industry.
Why Choose Code with TLS?
At Code with TLS, we understand the importance of quality education and hands-on experience when it comes to IT training. Whether you’re a beginner looking to start your career or a professional aiming to upskill, we offer a variety of tech courses tailored to meet your specific needs. Here’s why you should choose us:
Industry-Relevant Courses Our courses are designed to keep up with the rapidly changing tech industry. We offer training in Digital Marketing, Data Science, Mobile App Development, MERN Stack, AI/ML, and much more. These programs are curated to ensure that you acquire the skills that are in high demand by employers.
Expert Trainers and Practical Learning Our trainers are highly experienced professionals who have worked in the tech industry for years. They use practical examples, real-world case studies, and interactive methods to make learning engaging and effective. At Code with TLS, we emphasize hands-on training, ensuring you gain the practical skills necessary to excel.
100% Placement Assistance We not only equip you with industry-relevant skills but also provide placement assistance to help you land your dream job. With over 650 placement partners, our alumni have gone on to work with some of the best companies in the tech industry, earning impressive salaries and career growth.
Flexible Learning Options Whether you prefer to attend classes offline or take advantage of online learning, Code with TLS offers flexible options to accommodate your schedule. Our IT Training Institute Near Me ensures that learning is accessible to everyone, no matter where you're located.
Your Path to a Successful Tech Career Starts Here
If you’re ready to invest in your future and take your career to the next level, Code with TLS is the Tech Course Provider you can trust. Our training programs are designed to be comprehensive, easy to understand, and most importantly, tailored to meet the needs of today’s tech-driven world.
Ready to start your journey with Code with TLS? Call us now at +918527866980 to learn more about our courses and how we can help you achieve your career goals!
#IT Training Institute Near Me#Tech Course Provider#Best IT Training Institute#Tech Courses Near Me#Digital Marketing Courses#Data Science Training#Mobile App Development Courses#MERN Stack Training#AI/ML Courses#IT Training Institute#Tech Career Courses#Code with TLS#Job-Oriented Tech Courses#Online IT Training#IT Courses Near Me#Best Tech Courses in India#Placement Assistance Tech Courses#Tech Skills Training#Tech Career Development#Learn Coding and Programming#Tech Training Programs
0 notes
Text
Generative AI | High-Quality Human Expert Labeling | Apex Data Sciences
Apex Data Sciences combines cutting-edge generative AI with RLHF for superior data labeling solutions. Get high-quality labeled data for your AI projects.
#GenerativeAI#AIDataLabeling#HumanExpertLabeling#High-Quality Data Labeling#Apex Data Sciences#Machine Learning Data Annotation#AI Training Data#Data Labeling Services#Expert Data Annotation#Quality AI Data#Generative AI Data Labeling Services#High-Quality Human Expert Data Labeling#Best AI Data Annotation Companies#Reliable Data Labeling for Machine Learning#AI Training Data Labeling Experts#Accurate Data Labeling for AI#Professional Data Annotation Services#Custom Data Labeling Solutions#Data Labeling for AI and ML#Apex Data Sciences Labeling Services
1 note
·
View note
Text
Role of Python and its uses in AI and Machine Learning

Python is vital in AI & ML due to its extensive libraries, and community support. It is used for data preprocessing, evaluation, and deployment, making it the language for developing AI and ML apps. To know more read this blog from CodeSquadz.
#role of python in ai and data science#python for ml#python for ai#python for ai and ml#python training
0 notes